
The Complete Claude /goal Guide for AI Agents 🤖
What Claude /goal actually is, why most invocations fail, and how to write production-grade goal conditions for financial research, backtesting, and live market monitoring.

👋 Hey, Linas here! Every day, I break down 3 stories shaping the future of FinTech & Artificial Intelligence - plus the money movements and trends worth tracking. First time here? 380k+ FinTech and AI leaders get this daily. Join them:
Every serious AI practitioner working in fintech or tech eventually runs into the same wall. You give an agent a complex task - a sector deep dive, a backtesting pipeline, a daily intelligence digest - and it either halts for confirmation every three steps, loops indefinitely without finishing, or delivers a plausible-looking output that quietly fails to meet the actual requirements.
The bottleneck is rarely the model. It’s the spec.
/goal is Claude Code’s mechanism for turning a session into an autonomous loop: the agent runs, verifies whether the goal condition is met, and continues until it is - without checking in with you.
When used correctly, you define the end state, configure the harness, and return to finished work. When used naively - which is how most people use it - you return to either a frozen session or a confident-sounding mess.
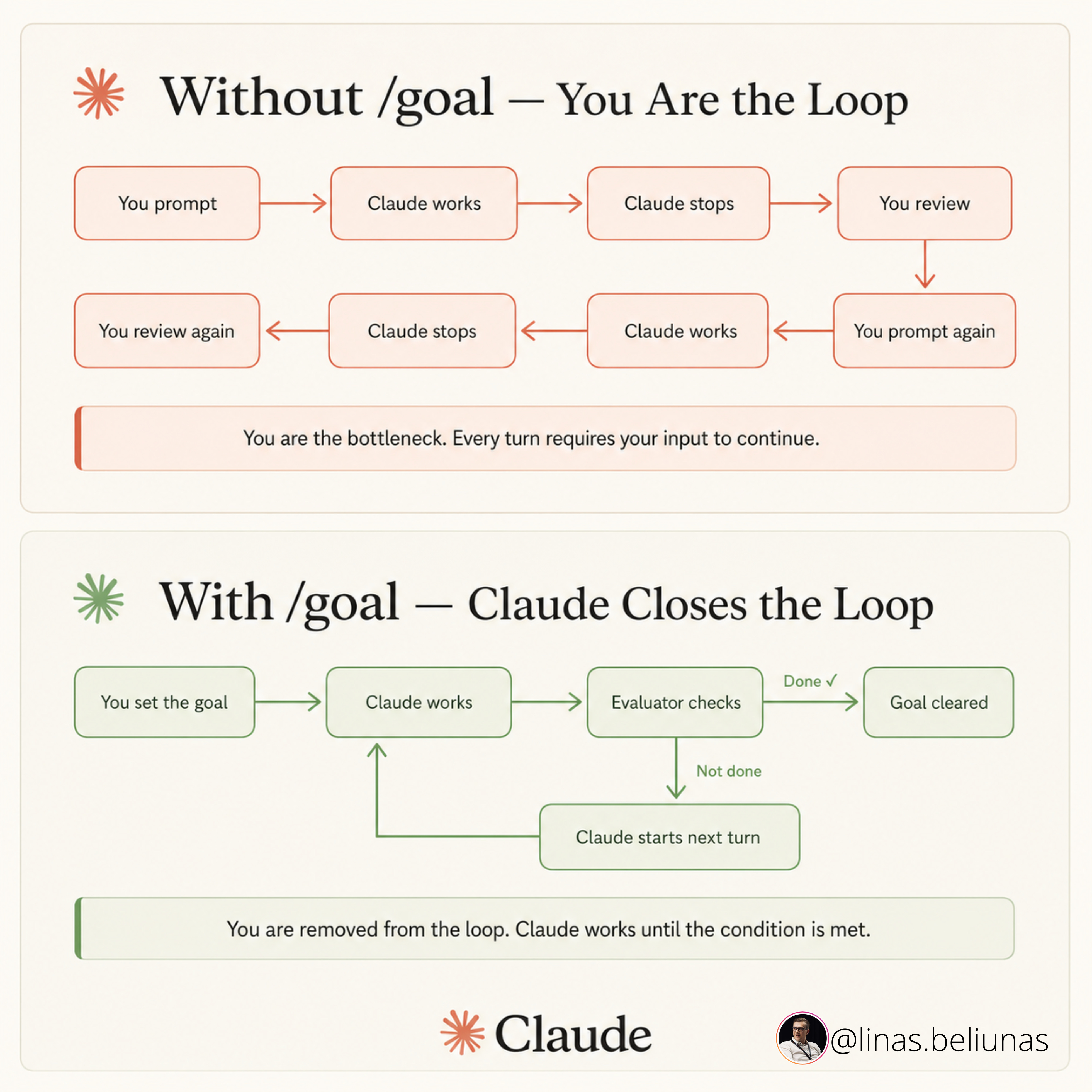
This guide therefore covers:
How
/goalactually evaluates conditions (and why most conditions are unevaluable)The three-element formula for writing conditions that work
The reliability architecture that determines whether a multi-hour agent run completes, and
Three production-grade prompt templates built for the workflows that matter most in fintech - deep competitive research, code-heavy builds like backtests and dashboards, and ongoing portfolio and market monitoring.
Bonus: Two companion pieces that pair directly with the templates above - The System for Never Hitting Claude’s Limits, covering the context engineering and model selection discipline that keeps long
/goalruns from burning your allocation, and an End-to-End Guide to Claude Code Routines, with copy-paste routines for autonomous code review, deploy verification, and deal flow screening.
It also addresses a widespread misconception that “zero hand-holding” is an engineering outcome rather than a marketing claim. Context rot silently degrades long runs well before the window fills. Anthropic’s own research on long-running agents shows that reliability comes from the harness, not the model.
And for fintech founders & operators, what every generic framework omits - data sensitivity tiers, environment segregation, regulatory output flagging, simulation-only constraints - can mean the difference between a useful research agent and an operational liability.
Let’s dive in.